
贝叶斯定理
-
TheMatrix楼主

- 论坛元老

2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 296
- 帖子: 13960
- 注册时间: 2022年 7月 26日 00:35
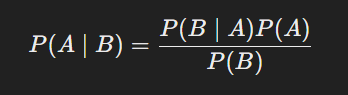

-
TheMatrix楼主
- 论坛元老
2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 296
- 帖子: 13960
- 注册时间: 2022年 7月 26日 00:35

-
TheMatrix楼主
- 论坛元老
2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 296
- 帖子: 13960
- 注册时间: 2022年 7月 26日 00:35

-
TheMatrix楼主
- 论坛元老
2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 296
- 帖子: 13960
- 注册时间: 2022年 7月 26日 00:35

#7 Re: 贝叶斯定理
贝叶斯学派的精髓在于参数估计。最简单的,投硬币的结果是binomial,有个参数p。这个参数p有个分布,好像是beta分布。注意参数p不是一个确定的值而是一个分布。你什么都没观测时,beta分布就是p是0.5的概率最大。然后随着你不断看到投掷结果,beta分布不断更新。beta分布有两个参数a和b。一开始都是1。如果投出来是0, a+1,是1,b+1。参数估计的算法就是counting。直到趋近这块作了敝的硬币的真实概率。所有常见的分布都有参数对应的先验分布。
这套系统后来又被推广到贝叶斯网络用来做参数估计,复杂性差不多到了可编程的程度。在CNN突破前,贝叶斯学派统治了机器视觉二十来年。关键字是graphical model和gibbs sampling。代表人物是伯克利的迈克尔乔丹。而且当时这类模型就叫"generative model",和以SVM为代表的discriminative model对着干。还有个bishop在贝叶斯理论的框架下写了一本经典的机器学习和模式识别著作也非常有名。这本书写得非常优美,如果想感受下贝叶斯学派的美学可以看下第一章。
每次经验拟合派快要走不下去的时候贝叶斯主义都会死灰复燃。
x1

上次由 wdong 在 2025年 1月 23日 15:56 修改。
-
changjiang
- 论坛精英

- 帖子互动: 484
- 帖子: 7150
- 注册时间: 2022年 7月 22日 21:59
-
changjiang
- 论坛精英
- 帖子互动: 484
- 帖子: 7150
- 注册时间: 2022年 7月 22日 21:59
#9 Re: 贝叶斯定理
你这是技术层面的理解。哲学层面的理解上面video 讲了。wdong 写了: 2025年 1月 23日 15:35 贝叶斯学派的精髓在于参数估计。最简单的,投硬币的结果是binomial,有个参数p。这个参数p有个分布,好像是beta分布。注意参数p不是一个确定的值而是一个分布。你什么都没观测时,beta分布就是p是0.5的概率最大。然后随着你不断看到投掷结果,beta分布不断更新。beta分布有两个参数a和b。一开始都是1。如果投出来是0, a+1,是1,b+1。参数估计的算法就是counting。直到趋近这块作了敝的硬币的真实概率。所有常见的分布都有参数对应的先验分布。
这套系统后来又被推广到贝叶斯网络用来做参数估计,复杂性差不多到了可编程的程度。在CNN突破前,贝叶斯学派统治了机器视觉二十来年。关键字是graphical model和gibbs sampling。代表人物是伯克利的迈克尔乔丹。还有个bishop在贝叶斯理论的框架下写了一本经典的机器学习和模式识别著作也非常有名。这本书写得非常优美,如果想感受下贝叶斯学派的美学可以看下第一章。
每次经验拟合派快要走不下去的时候贝叶斯主义都会死灰复燃。
-
TheMatrix楼主
- 论坛元老
2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 296
- 帖子: 13960
- 注册时间: 2022年 7月 26日 00:35




-
TheMatrix楼主
- 论坛元老
2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 296
- 帖子: 13960
- 注册时间: 2022年 7月 26日 00:35
#13 Re: 贝叶斯定理
嗯。你这个说的很好。
这两天我也看了一下。前面的几个资料都看了。我说一下目前的认识。
从prior和posterior的名字来看,这里存在一个迭代修正的过程。修正的目标是参数。
参数是什么?参数可以想象成大脑对一个事物的认知状态。所以这不是一个数,至少是一组数,可能是大量的一组数,这叫 *一个* 参数。而这样一个参数中的每一个数还可以变动,形成一个参数空间,一个非常高维的空间。迭代修正的目标是这个参数空间上的概率分布。这是一种全面的认知状态,有了这个认知状态,比如就能很容易知道哪一个参数是最好的,也就是概率是最大的。
具体到一个问题,肯定要缩小这个空间。比如curve fitting,有一组样本X,每一个样本点都有(x,y),要找到一个曲线,拟合这个样本。而且还要有泛化能力,也就是样本之外新出现一个点,仍然可以被这个曲线近似。
大脑思考这个问题的话,参数空间太大了,无从下手。所以首先要定一个model,比如polynomial curve fitting,然后再定一个最高阶数,比如只考虑9阶polynomial。那么这个参数空间就是9维的空间,每一个点是一个参数,而每一个参数有9个分量。而之前先定下的那些设定,比如model的选取,以及最高阶数等于9,这些可以叫hyperparameters。
P(θ|X) = P(X|θ)P(θ)/P(X)
可以看成是
P(θ) --------> P(θ|X)
也就是先验分布到后验分布的一个修正过程,用事件X进行修正。
P(θ)写成ft,P(θ|X)写成ft+1,所以这个过程写成
ft --------> ft+1
这样就迭代下去了。
ft和ft+1是θ所在的空间,也就是参数空间,上的概率分布。P(X)不随θ变化,起到的是归一化的作用。
最开始的先验分布不重要,因为这个链条是很长的:
f0 --> f1 --> f2 --> ... --> ft --------> ft+1
f0怎么选不重要,它会被一连串的事件X1,X2,...修正到收敛。这是我们对认知的一个假设。
上次由 TheMatrix 在 2025年 1月 26日 11:04 修改。
原因: 未提供修改原因
原因: 未提供修改原因