此帖转自 redot 在 股海弄潮(Stock) 的帖子:Re: Deepseek的谎言会一步步掰开吧
来, 搬砖
1)论文在这里 https://arxiv.org/html/2501.12948v1
2)不愿读论文的,看这个
or 这个
3)看不懂,就看这个 https://finance.sina.com.cn/roll/2025-0 ... 0935.shtml
or 这个 https://zhuanlan.zhihu.com/p/19530895760
看了以后再BB,稍微合理点点
Deepseek系列论文及讲解
版主: verdelite, TheMatrix
-
TheMatrix楼主

- 论坛支柱

2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 261
- 帖子: 13182
- 注册时间: 2022年 7月 26日 00:35

-
TheMatrix楼主
- 论坛支柱
2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 261
- 帖子: 13182
- 注册时间: 2022年 7月 26日 00:35
#3 Re: Deepseek系列论文及讲解
DeepSeek v3:
https://arxiv.org/html/2412.19437v1
Abstract
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
https://arxiv.org/html/2412.19437v1
Abstract
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
x1

上次由 TheMatrix 在 2025年 2月 4日 10:10 修改。
原因: 未提供修改原因
原因: 未提供修改原因

#4 Re: Deepseek系列论文及讲解
这些做DeepLearning的真是Hinton的徒子徒孙,没点理论修养(连计算理论甚至计算机理论的常识都没有),就开干,开讲。开干危害不大,顶多就是摸索错了,开讲可就不然了,经常是一本正经地胡说八道:什么AGI,什么emergence(我真想抽这术语发明者一个耳光)。计算理论和计算机科技不是物理,可以猜,它是先有理论后有技术或实现,搞什么AGI,什么推理,编程,他们说的是一回事,做的是另外一回事。太搞笑了。TheMatrix 写了: 2025年 2月 4日 09:47 此帖转自 redot 在 股海弄潮(Stock) 的帖子:Re: Deepseek的谎言会一步步掰开吧
来, 搬砖
1)论文在这里 https://arxiv.org/html/2501.12948v1
2)不愿读论文的,看这个
or 这个
3)看不懂,就看这个 https://finance.sina.com.cn/roll/2025-0 ... 0935.shtml
or 这个 https://zhuanlan.zhihu.com/p/19530895760
看了以后再BB,稍微合理点点
对DeepSeek的原创性持怀疑态度,让子弹再飞一会儿。但也不喜欢搞技术封锁,知识要共享。
x1

上次由 forecasting 在 2025年 2月 4日 11:47 修改。
#5 Re: Deepseek系列论文及讲解
都不如看这个
Lex Fridman自己就是干人工智能的,估计问问题也能问在点子上,就是太特么长了,5个小时!不过嘉宾显然是敬畏DeepSeek的。
Nathan开头就说中国同行是好同志:
“DeepSeek is doing fantastic work for disseminating understanding of AI, their papers are extremely detailed in what they do and for other teams around the world, they’re very actionable in terms of improving your own training technics”
还夸他们的研究:
“published a lot details, especially in v3, they were very clear that they were doing interventions on the technical stack that go at many different levels - for examples, to get highly efficient trainings, they’re making modifications at or below Cuda layer for NVDIA chips, I have never worked there myself, there are only a few peoples in the world that do that very well and some of them are from DeepSeek and these type of people are at DeepSeek and leading American frontier labs but there are not many places”
我也不懂哈,但感觉这哥们儿是被震住了。
Lex Fridman自己就是干人工智能的,估计问问题也能问在点子上,就是太特么长了,5个小时!不过嘉宾显然是敬畏DeepSeek的。
Nathan开头就说中国同行是好同志:
“DeepSeek is doing fantastic work for disseminating understanding of AI, their papers are extremely detailed in what they do and for other teams around the world, they’re very actionable in terms of improving your own training technics”
还夸他们的研究:
“published a lot details, especially in v3, they were very clear that they were doing interventions on the technical stack that go at many different levels - for examples, to get highly efficient trainings, they’re making modifications at or below Cuda layer for NVDIA chips, I have never worked there myself, there are only a few peoples in the world that do that very well and some of them are from DeepSeek and these type of people are at DeepSeek and leading American frontier labs but there are not many places”
我也不懂哈,但感觉这哥们儿是被震住了。

#6 Re: Deepseek系列论文及讲解
对,他在MIT开过AI的课benadryl 写了: 2025年 2月 4日 11:43 都不如看这个
Lex Fridman自己就是干人工智能的,估计问问题也能问在点子上,就是太特么长了,5个小时!不过嘉宾显然是敬畏DeepSeek的。
Nathan开头就说中国同行是好同志:
“DeepSeek is doing fantastic work for disseminating understanding of AI, their papers are extremely detailed in what they do and for other teams around the world, they’re very actionable in terms of improving your own training technics”
还夸他们的研究:
“published a lot details, especially in v3, they were very clear that they were doing interventions on the technical stack that go at many different levels - for examples, to get highly efficient trainings, they’re making modifications at or below Cuda layer for NVDIA chips, I have never worked there myself, there are only a few peoples in the world that do that very well and some of them are from DeepSeek and these type of people are at DeepSeek and leading American frontier labs but there are not many places”
我也不懂哈,但感觉这哥们儿是被震住了。
-
TheMatrix楼主
- 论坛支柱
2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 261
- 帖子: 13182
- 注册时间: 2022年 7月 26日 00:35
#7 Re: Deepseek系列论文及讲解
R1: https://arxiv.org/html/2501.12948v1
V3: https://arxiv.org/html/2412.19437v1
有这么几个东西:
DeepSeek-R1
DeepSeek-R1-Zero
DeepSeek-V3
DeepSeek-V3-base
它们的关系是这样的:
1,它们研发的时间有交叉,但是基本上V3比R1早一些。
2,V3-base是V3的base model,这是个大语言模型,670B。但是它也是低成本的。低成本主要的原因应该是数据蒸馏。DeepSeek还列出了很多其他技术原因,但我觉得主要原因是数据蒸馏。
3,V3中除了base model之外也有reasoning,是用supervised fine-tune加reinforcement learning训练的。这属于post-training。
4,R1-Zero是在V3-base基础上训练的,直接用reinforcement learning训练,没有supervised fine-tune。
5,R1是在R1-Zero基础上加一点人工干预,应该算alignment。
6,R1的context比V3的context长。也就是问问题本身可以很长很长,一本书可以直接扔进去。思考时间也比V3长,得到的结果也长。
V3: https://arxiv.org/html/2412.19437v1
有这么几个东西:
DeepSeek-R1
DeepSeek-R1-Zero
DeepSeek-V3
DeepSeek-V3-base
它们的关系是这样的:
1,它们研发的时间有交叉,但是基本上V3比R1早一些。
2,V3-base是V3的base model,这是个大语言模型,670B。但是它也是低成本的。低成本主要的原因应该是数据蒸馏。DeepSeek还列出了很多其他技术原因,但我觉得主要原因是数据蒸馏。
3,V3中除了base model之外也有reasoning,是用supervised fine-tune加reinforcement learning训练的。这属于post-training。
4,R1-Zero是在V3-base基础上训练的,直接用reinforcement learning训练,没有supervised fine-tune。
5,R1是在R1-Zero基础上加一点人工干预,应该算alignment。
6,R1的context比V3的context长。也就是问问题本身可以很长很长,一本书可以直接扔进去。思考时间也比V3长,得到的结果也长。
x1

#9 Re: Deepseek系列论文及讲解
会聊天吧?学术成就未必有多高,我外行哈,看wiki条目感觉他就是2019年被老马钦点然后傍上了老马开始出名的?不过肯定是podcast主持人里最懂AI的所以他采访AI大佬的视频我都认真看了。

#11 Re: Deepseek系列论文及讲解
你们到现在都没看懂为什么所有人都知道deepseek作假但是拼着往上凑。因为deepshit开创了广大的骗钱机会,毕竟如果都和openai这么玩,所有钱都去了openai这几家大模型,deepshit让每个人都可以加入骗钱的行列。lol
TheMatrix 写了: 2025年 2月 4日 09:47 此帖转自 redot 在 股海弄潮(Stock) 的帖子:Re: Deepseek的谎言会一步步掰开吧
来, 搬砖
1)论文在这里 https://arxiv.org/html/2501.12948v1
2)不愿读论文的,看这个
or 这个
3)看不懂,就看这个 https://finance.sina.com.cn/roll/2025-0 ... 0935.shtml
or 这个 https://zhuanlan.zhihu.com/p/19530895760
看了以后再BB,稍微合理点点
x1
If printing money would end poverty, printing diplomas would end stupidity.
-
TheMatrix楼主
- 论坛支柱
2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 261
- 帖子: 13182
- 注册时间: 2022年 7月 26日 00:35
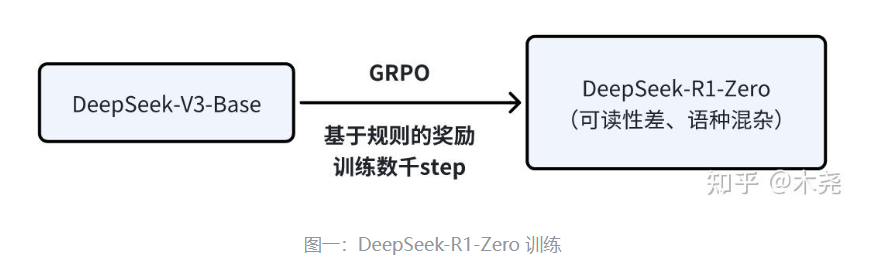
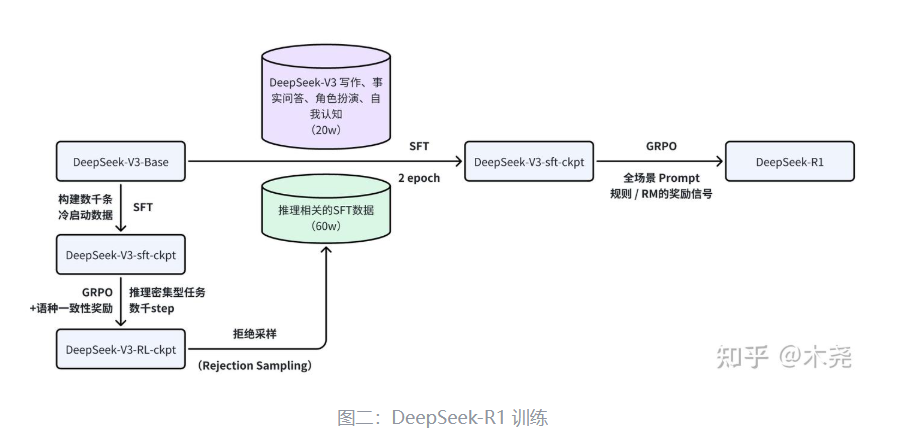
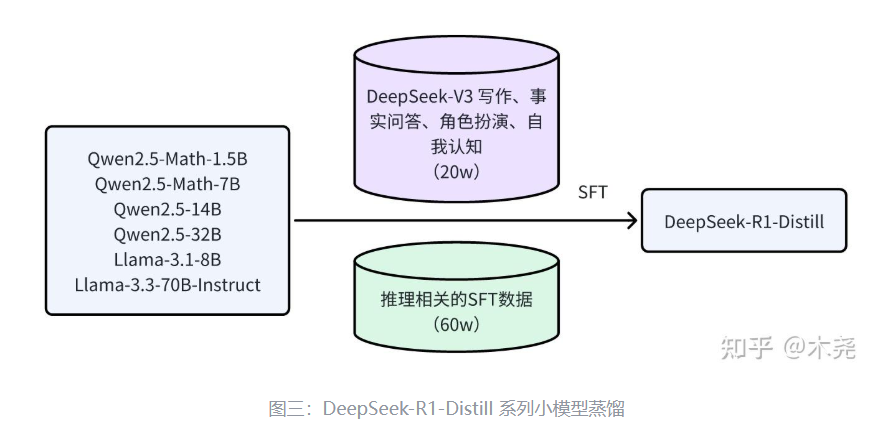
-
TheMatrix楼主
- 论坛支柱
2024年度优秀版主
TheMatrix 的博客 - 帖子互动: 261
- 帖子: 13182
- 注册时间: 2022年 7月 26日 00:35
-
Caravel
- 论坛元老

Caravel 的博客 - 帖子互动: 528
- 帖子: 23967
- 注册时间: 2022年 7月 24日 17:21
#14 Re: Deepseek系列论文及讲解
V3成本低主要是架构创新,活跃参数很少,蒸馏顶多能减少点他们数据收集成本TheMatrix 写了: 2025年 2月 4日 17:52 R1: https://arxiv.org/html/2501.12948v1
V3: https://arxiv.org/html/2412.19437v1
有这么几个东西:
DeepSeek-R1
DeepSeek-R1-Zero
DeepSeek-V3
DeepSeek-V3-base
它们的关系是这样的:
1,它们研发的时间有交叉,但是基本上V3比R1早一些。
2,V3-base是V3的base model,这是个大语言模型,670B。但是它也是低成本的。低成本主要的原因应该是数据蒸馏。DeepSeek还列出了很多其他技术原因,但我觉得主要原因是数据蒸馏。
3,V3中除了base model之外也有reasoning,是用supervised fine-tune加reinforcement learning训练的。这属于post-training。
4,R1-Zero是在V3-base基础上训练的,直接用reinforcement learning训练,没有supervised fine-tune。
5,R1是在R1-Zero基础上加一点人工干预,应该算alignment。
6,R1的context比V3的context长。也就是问问题本身可以很长很长,一本书可以直接扔进去。思考时间也比V3长,得到的结果也长。