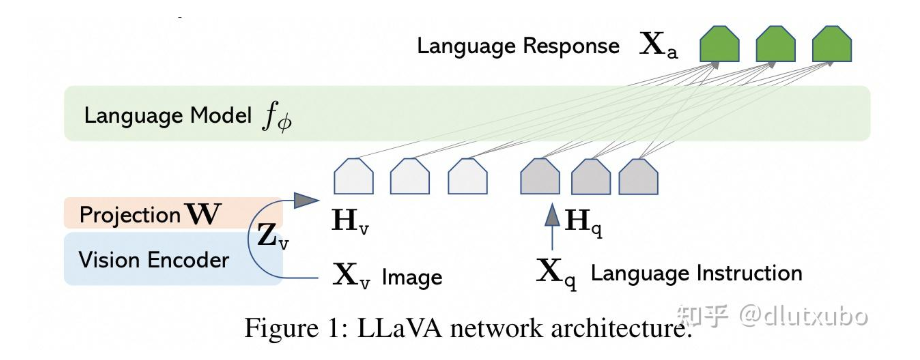
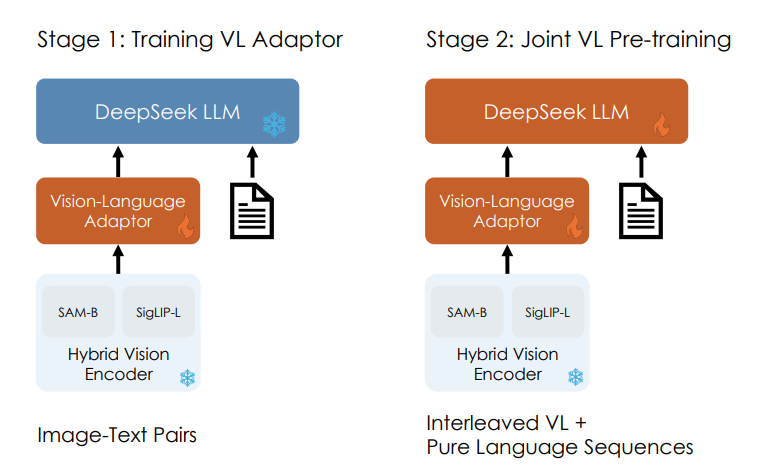
#21 Re: 世界模型
发表于 : 2025年 1月 9日 16:12
这一点指出的是这个方法的“合理性”。概念是有大小的,概念之间是有关系的。不分大小,不管概念之间的关系,硬输入模型,效果绝对是差的。TheMatrix 写了: 2025年 1月 9日 15:57 2. 把世界知识变成文本,这本身就是对概念大小的一种分析归纳和总结。大的概念就应该更频繁的出现在语句之中。说大和小已经不准确了。“爱”和“苹果”这两个概念谁大?已经不是大小的简单关系了。世界知识文本的整体,就给出了所有概念之间的关系。
但是概念大小,概念之间的关系怎么表示?以神经网络的连接来表示吗?怎么连接?怎么架构?不知道。
但是,把世界知识变成语言,从外部来表示概念之间的关系,以数据的形势输入“现有”的语言模型。这是我在这一波AI发展中,屡次被教育了的。