分页: 2 / 4
#21 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 13:16
由 rtyu
看懂了,是用训练chatgpt的方法用开车录像训练人工智能开车,现在进一步了解其危险性了.
#22 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 14:29
由 ignius
在规划模块中用ai代替了rule based,只要训练量足够,要比rule based强很多。因为在人类开车中总会有rule没法cover的边界条件。而AI直接从大量的人类实际驾车中总结出经验。
这个视频解释了这个问题。
VIDEO rtyu 写了: 2025年 1月 4日 13:16
看懂了,是用训练chatgpt的方法用开车录像训练人工智能开车,现在进一步了解其危险性了.
#23 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 15:43
由 rtyu
用了八个摄像头要比人眼看到的更多,也就是需要比人眼能看到的更多图像信息,看来还是更多的信息的有利于自动驾驶的。那为什么不用激光和雷达提供更多路况信息?拿来训练人工智能智能也有帮助,人工智能训练没有嫌训练信息太多的。可能Tesla还是为了节省成本,把激光和雷达给去除了。造车时连一两个螺栓都要省,激光和雷达这么昂贵的部件更应该省。
ignius 写了: 2025年 1月 4日 14:29
在规划模块中用ai代替了rule based,只要训练量足够,要比rule based强很多。因为在人类开车中总会有rule没法cover的边界条件。而AI直接从大量的人类实际驾车中总结出经验。
这个视频解释了这个问题。
VIDEO
#24 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 15:51
由 pathdream
lexian 写了: 2025年 1月 4日 06:33 VIDEO
这个? 虽然四年前的FSD algorithm 还很初级, 没有认出路上横躺的卡车(极小概率事件)而提早变道避免碰撞-这个视频清晰展示FSD起的作用,车子在最后急刹车。 车身完好, 没有人员伤亡。
狂赞斯拉 最后救了小白鼠
开油车的都换线了
#25 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 16:01
由 ignius
没错,就是为了节省成本,不被硬件控制。软件的迭代要容易得多。大家可以拭目以待,看看哪种方案最后能胜出。另外tesla最新的fsd hardware里是有个sar雷达的,只是没有lidar。
Tesla's Hardware 4 (HW4) Full Self-Driving (FSD) system includes a high-definition (HD) synthetic aperture radar (SAR) unit called Phoenix:
Purpose
The radar enhances situational awareness and adds precision to self-driving capabilities. It could potentially see better in low-light conditions, fog, rain, or snow.
Features
The radar is a forward-facing radar that extends the current reach by double. It's likely to be used for emergency braking and high accuracy near the front of the car.
rtyu 写了: 2025年 1月 4日 15:43
用了八个摄像头要比人眼看到的更多,也就是需要比人眼能看到的更多图像信息,看来还是更多的信息的有利于自动驾驶的。那为什么不用激光和雷达提供更多路况信息?拿来训练人工智能智能也有帮助,人工智能训练没有嫌训练信息太多的。可能Tesla还是为了节省成本,把激光和雷达给去除了。造车时连一两个螺栓都要省,激光和雷达这么昂贵的部件更应该省。
#26 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 16:09
由 ignius
另外你有些误解。纯视觉还是lidar,只是在感知这个模块的不同方法。在决定规划的模块,大家都需要海量数据来train ai。
只不过lidar更多是通过硬件来拿到所需的视频信息,纯视觉是通过软件来拿到。
rtyu 写了: 2025年 1月 4日 15:43
用了八个摄像头要比人眼看到的更多,也就是需要比人眼能看到的更多图像信息,看来还是更多的信息的有利于自动驾驶的。那为什么不用激光和雷达提供更多路况信息?拿来训练人工智能智能也有帮助,人工智能训练没有嫌训练信息太多的。可能Tesla还是为了节省成本,把激光和雷达给去除了。造车时连一两个螺栓都要省,激光和雷达这么昂贵的部件更应该省。
#27 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 17:49
由 fantasist
ignius 写了: 2025年 1月 4日 14:29
在规划模块中用ai代替了rule based,只要训练量足够,要比rule based强很多。因为在人类开车中总会有rule没法cover的边界条件。而AI直接从大量的人类实际驾车中总结出经验。
这个视频解释了这个问题。
VIDEO
既然你提到这么多AI名词,我假设你懂rule based碰到对应的条件100%触发训练时提供的label行为,而neural network甚至都不能保证inference时给训练数据中存在的输入,输出一定跟label一样。所以新模型提高了障碍物识别问题的能力是可信,毕竟训练数据扩充了,loss下降了,但要说纯视觉模型solution解决了这个问题,那就是胡扯了。
#28 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 20:24
由 ignius
感觉你没看懂我贴的第一个视频。我说的tesla解决障碍物识别问题是运用了occupancy network,是属于感知层面。它不一定知道前面是什么障碍物,但是通过occupant network,它能知道有障碍物以及它的形状,occupancy volume & occupancy flow。
所谓的rule based说的是是规划层面。原来fsd的规划层面用的都是rule based和树搜索,2023年开始改成类似ChatGPT的神经网络和transformer。
fantasist 写了: 2025年 1月 4日 17:49
既然你提到这么多AI名词,我假设你懂rule based碰到对应的条件100%触发训练时提供的label行为,而neural network甚至都不能保证inference时给训练数据中存在的输入,输出一定跟label一样。所以新模型提高了障碍物识别问题的能力是可信,毕竟训练数据扩充了,loss下降了,但要说纯视觉模型solution解决了这个问题,那就是胡扯了。
#29 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 20:33
由 fantasist
ignius 写了: 2025年 1月 4日 20:24
感觉你没看懂我贴的第一个视频。我说的tesla解决障碍物识别问题是运用了occupancy network,是属于感知层面。它不一定知道前面是什么障碍物,但是通过occupant network,它能知道有障碍物以及它的形状,还有避开它的路径occupancy flow。
所谓的rule based说的是是规划层面。原来fsd的规划层面用的都是rule based和树搜索,2023年开始改成类似ChatGPT的神经网络和transformer。
occupancy network也是neural network,这种推理时的不确定性依然存在。看来你没做过ML,被tesla各种宣传忽悠了。
#30 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 20:51
由 ignius
你没看视频吧?occupancy network输出的结果还会跟nerf的结果进行比较。
fantasist 写了: 2025年 1月 4日 20:33
occupancy network也是neural network,这种推理时的不确定性依然存在。看来你没做过ML,被tesla各种宣传忽悠了。
#31 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 21:06
由 fantasist
ignius 写了: 2025年 1月 4日 20:51
你没看视频吧?occupancy network输出的结果还会跟nerf的结果进行比较。
不是,你看严肃视频之前不点开youtuber的profile看一下他大致水平是如何吗……想研究技术,看这种营销号纯粹浪费时间,不如搜几篇相关论文丢给AI总结一下。
#32 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 4日 21:14
由 ignius
那个视频是我今天才找到的,因为是用中文讲解的很清楚的。
至于tesla fsd 相关的,我看的是fsd负责人自己发的视频。很长,烙印英语,这里同学估计没人会看完。
VIDEO https://www.thinkautonomous.ai/blog/occ ... works/amp/
fantasist 写了: 2025年 1月 4日 21:06
不是,你看严肃视频之前不点开youtuber的profile看一下他大致水平是如何吗……想研究技术,看这种营销号纯粹浪费时间,不如搜几篇相关论文丢给AI总结一下。
#33 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 5日 10:56
由 geniushanbiao
ignius 写了: 2025年 1月 4日 16:09
另外你有些误解。纯视觉还是lidar,只是在感知这个模块的不同方法。在决定规划的模块,大家都需要海量数据来train ai。
只不过lidar更多是通过硬件来拿到所需的视频信息,纯视觉是通过软件来拿到。
软件得到的信息和硬件得到的信息比可靠性是一样的么?
#34 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 5日 12:28
由 ignius
已经很接近了。所谓的软件得到信息,指的是把摄像头获取的2d视频信息用软件算法转换成3d视频,再加上depth。最近occupancy network很火,很多公司都在这方面科研。有兴趣的同学可以看看这个视频:
VIDEO
#35 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 5日 13:02
由 ignius
我觉得tesla一根筋的搞纯视觉fsd,也是为了以后的ai机器人做技术储备。机器人以后单价应该是2万美金左右,装lidar就不太现实了,还是要靠纯视觉。
#36 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 5日 14:35
由 geniushanbiao
ignius 写了: 2025年 1月 5日 12:28
已经很接近了。所谓的软件得到信息,指的是把摄像头获取的2d视频信息用软件算法转换成3d视频,再加上depth。最近occupancy network很火,很多公司都在这方面科研。有兴趣的同学可以看看这个视频:
VIDEO
接近和相同是两个概念。我希望看到客观的数据对比而不是这种无聊的定性分析。
#37 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 5日 14:45
由 ignius
有测试啊,我发的那个视频里就有演示。
geniushanbiao 写了: 2025年 1月 5日 14:35
接近和相同是两个概念。我希望看到客观的数据对比而不是这种无聊的定性分析。
#38 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 5日 15:25
由 fantasist
ignius 写了: 2025年 1月 5日 12:28
已经很接近了。所谓的软件得到信息,指的是把摄像头获取的2d视频信息用软件算法转换成3d视频,再加上depth。最近occupancy network很火,很多公司都在这方面科研。有兴趣的同学可以看看这个视频:
VIDEO
论文都号称自己是sota,测试集准确率多少?有85%吗
#39 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 5日 15:28
由 Jason6278
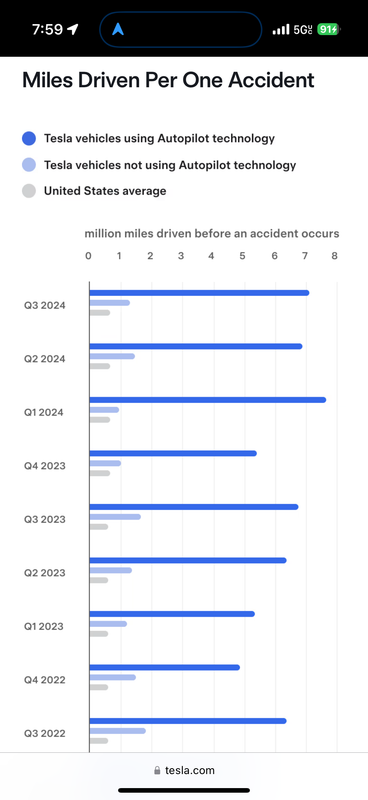
lexian 写了: 2025年 1月 3日 21:01
Well, about 10 times less likely to be in an accident with Tesla+FSD vs regular car.
阿姆斯特丹每年有一百多辆车掉河里,其中最多的就是特斯拉。
#40 Re: (转载)完了,BYD加女司机,渗入
发表于 : 2025年 1月 5日 15:44
由 ignius
对于大型物体检测的accuracy 几乎是100%了,小形物体还有恶劣天气,照明情况下85-90%左右吧,所以tesla fsd还需要nerf来supervise ON的输出。这方面每个fsd版本都在提高。
fantasist 写了: 2025年 1月 5日 15:25
论文都号称自己是sota,测试集准确率多少?有85%吗