
可以argue 初步解决hci 写了: 2025年 1月 20日 22:59 Llm就是解决一个知觉问题。
现在的Llm解决这个解决得好不好,那是另外一个问题。我认为算初步解决了,相信以后会解决得更好。
但就算完全解决了,也只是智能的初级阶段。
我就是这个意思,这当然也是心理学主流观点。并不出奇。
当然社会还没认识到这个观点,也不承认。如此而已。
但为啥以后会解决的更好
也就是说llm一直加大力道可以一直有incremental improvement?
但据说现在已经有瓶颈了
版主: hci
可以argue 初步解决hci 写了: 2025年 1月 20日 22:59 Llm就是解决一个知觉问题。
现在的Llm解决这个解决得好不好,那是另外一个问题。我认为算初步解决了,相信以后会解决得更好。
但就算完全解决了,也只是智能的初级阶段。
我就是这个意思,这当然也是心理学主流观点。并不出奇。
当然社会还没认识到这个观点,也不承认。如此而已。
hahan 写了: 2025年 1月 20日 23:02 可以argue 初步解决
但为啥以后会解决的更好
也就是说llm一直加大力道可以一直有incremental improvement?
但据说现在已经有瓶颈了
哈哈,抓了个现行。hci 写了: 2025年 1月 20日 22:31 Datalog
https://en.m.wikipedia.org/wiki/Datalog
上面列了一堆实现,其中就有我的,叫Datalevin
duiduilu2 写了: 2025年 1月 21日 07:05 哈哈,抓了个现行。
我就觉得不会有人知道HCI做的东西,除了他自己。
果然,这个链接是他自己加上去的,在2020年自己加上去的。
curprev 22:06, 1 October 2020 Huahaiy talk contribs 33,267 bytes +234 →Free software/open source undo
人艰不拆。那些所谓的大佬,也得不断搞PR塑造人设。duiduilu2 写了: 2025年 1月 21日 07:05 哈哈,抓了个现行。
我就觉得不会有人知道HCI做的东西,除了他自己。
果然,这个链接是他自己加上去的,在2020年自己加上去的。
curprev 22:06, 1 October 2020 Huahaiy talk contribs 33,267 bytes +234 →Free software/open source undo

HCI,你真是个小屁孩啊。hci 写了: 2025年 1月 21日 11:25 哈哈,现行个啥?做个东西,基本的营销得做呀。否则不就真成了”除了自己,不会有人知道“了么?是我自己加的wiki条目,有问题么?
其实我这个东西还没有开始正式宣传,因为离达到我的roadmap 1.0的目标还有一些距离。就这,也不妨碍这个玩意上橘黄色网站首页几次了。Datalevin现在query比PostgreSQL快,全文搜索比Lucene快,这些都是值得骄傲的成果。
目前准备跟风搞个矢量相似度搜索,这个不准备自己写了,就整合别人的库。
当然下面最重要的,是扩展Datalog语法,让函数可以放入rule head里面,这样就图灵完备,可以1.0了。
1.0之后,才会开始写各种流行语言的驱动,开始正式宣传。


看来Datalog和只有select的SQL有点像。hci 写了: 2025年 1月 20日 22:31 Datalog
https://en.m.wikipedia.org/wiki/Datalog
上面列了一堆实现,其中就有我的,叫Datalevin
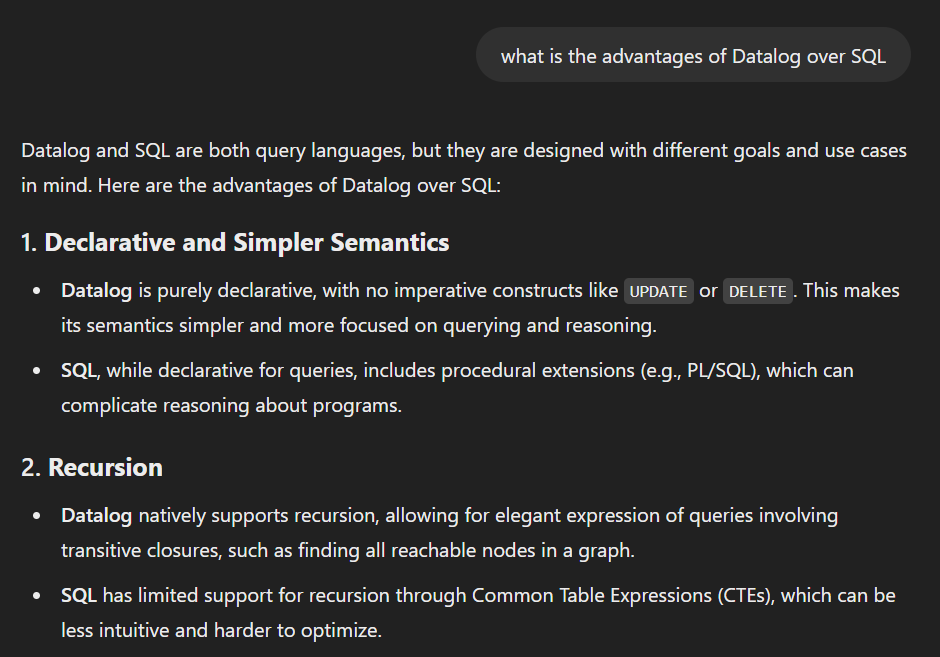




TheMatrix 写了: 2025年 1月 21日 14:29 看来Datalog和只有select的SQL有点像。
我这个问题问的是Datalog比SQL强的点。所以说的都是优点。
我很喜欢SQL,看来Datalog也要学一下。
可不可以多種coding agents左右互搏,對於同一個問題,python / c++ / java的輸入輸出達成共識,就自動證明coding大致是正確的,如果完全沒有共識,肯定是哪裡出問題了。這樣編程語言越多,LLM的coding越準確。wdong 写了: 2025年 1月 20日 20:11 这阵子折腾agent, 开始折腾出一些感觉来了。 一般的agent不可怕,可怕的是写程序的agent。写一般程序的agent也不可怕,其实真正可怕的只有一种agent,就是能改进自己程序的agent。我这个帖子要说的是,人和agent关于程序好坏是有不同的定义的。比如,对人来说,python比C++容易。但是对agent来说,同样的程序可能用C++写更容易。下面我根据我仅有的经验做出一个大胆的预测:
在Agent时代,碎片化的程序是好的程序。也就是说,每个文件放一个函数,或者一个什么最小的单元。目的就是修改对象定位到文件后, 在打开文件后面对的信息量尽可能少。然后整个项目分成几千几万个小文件。甚至都有可能数据库相比文件系统会更适合存储程序。
但是编程语言尤其自身的逻辑,范式转换并不意味着编程语言需要有大的改动。其实很多语言已经很碎片化了,比如java的包名可以套很多层。那么agent的范式就是再进一步,每个包就是一个函数,最底层的包名就是函数名。
你这个办法是对的。用不同的语言写多次,比同一个语言写多次好。magagop 写了: 2025年 1月 22日 16:45 可不可以多種coding agents左右互搏,對於同一個問題,python / c++ / java的輸入輸出達成共識,就自動證明coding大致是正確的,如果完全沒有共識,肯定是哪裡出問題了。這樣編程語言越多,LLM的coding越準確。
真理掌握在少数人手中。magagop 写了: 2025年 1月 22日 16:45 可不可以多種coding agents左右互搏,對於同一個問題,python / c++ / java的輸入輸出達成共識,就自動證明coding大致是正確的,如果完全沒有共識,肯定是哪裡出問題了。這樣編程語言越多,LLM的coding越準確。
你理解錯了,我是要「鑒偽」,如果N種語言得到的M個隨機輸入的輸出結果都相同,則程序正確的可信度越高,N和M越大越可信。反之,如果至少有一個結果不同,則生成的所有程序都未必可信。誰的數學好,能不能搞一個跟N和M相關的可信度函數?duiduilu2 写了: 2025年 1月 22日 18:42 真理掌握在少数人手中。
这个LLM的问题呢,恰恰是你所谓的共识,它以为真理在多数人手中。
这尼玛探讨真相的问题,靠投票能解决吗?
我只是记得当年希特勒发动很多德国科学家批判安因斯坦的相对论。
小孩对于世界的认知也是数据喂出来的。不过人类的训练数据来源就太多了:有自己的视觉(眼),三维距离(视差和手脚度量),有各种感觉反馈。而且这些数据之间天然的相互关联。比如看到
 ,感觉到炙热等等。语言模型的输入类型就单一了。
,感觉到炙热等等。语言模型的输入类型就单一了。




