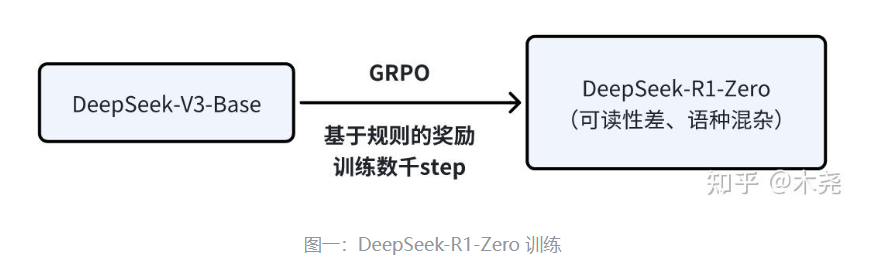
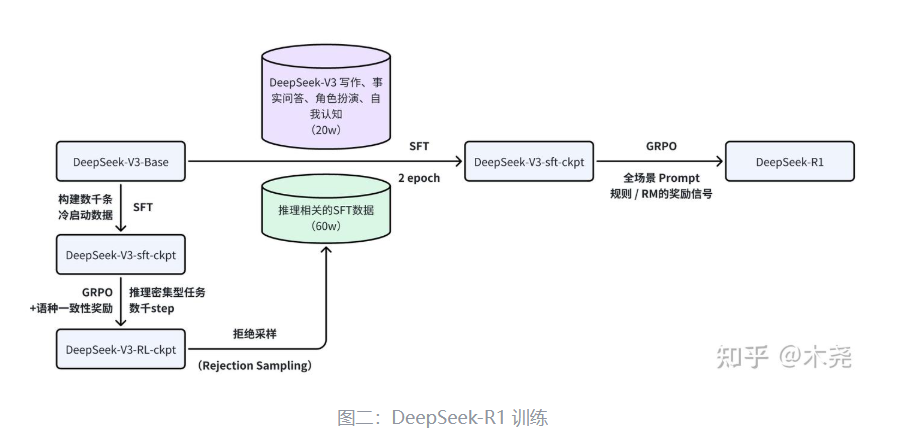
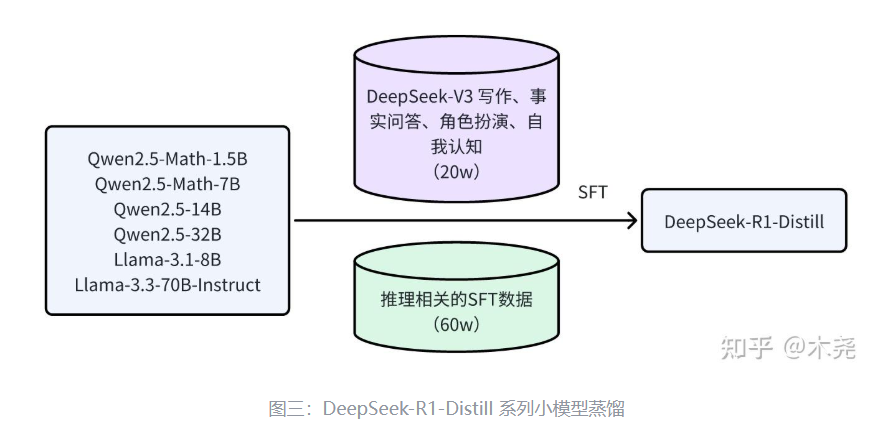
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
“DeepSeek is doing fantastic work for disseminating understanding of AI, their papers are extremely detailed in what they do and for other teams around the world, they’re very actionable in terms of improving your own training technics”
还夸他们的研究:
“published a lot details, especially in v3, they were very clear that they were doing interventions on the technical stack that go at many different levels - for examples, to get highly efficient trainings, they’re making modifications at or below Cuda layer for NVDIA chips, I have never worked there myself, there are only a few peoples in the world that do that very well and some of them are from DeepSeek and these type of people are at DeepSeek and leading American frontier labs but there are not many places”
“DeepSeek is doing fantastic work for disseminating understanding of AI, their papers are extremely detailed in what they do and for other teams around the world, they’re very actionable in terms of improving your own training technics”
还夸他们的研究:
“published a lot details, especially in v3, they were very clear that they were doing interventions on the technical stack that go at many different levels - for examples, to get highly efficient trainings, they’re making modifications at or below Cuda layer for NVDIA chips, I have never worked there myself, there are only a few peoples in the world that do that very well and some of them are from DeepSeek and these type of people are at DeepSeek and leading American frontier labs but there are not many places”