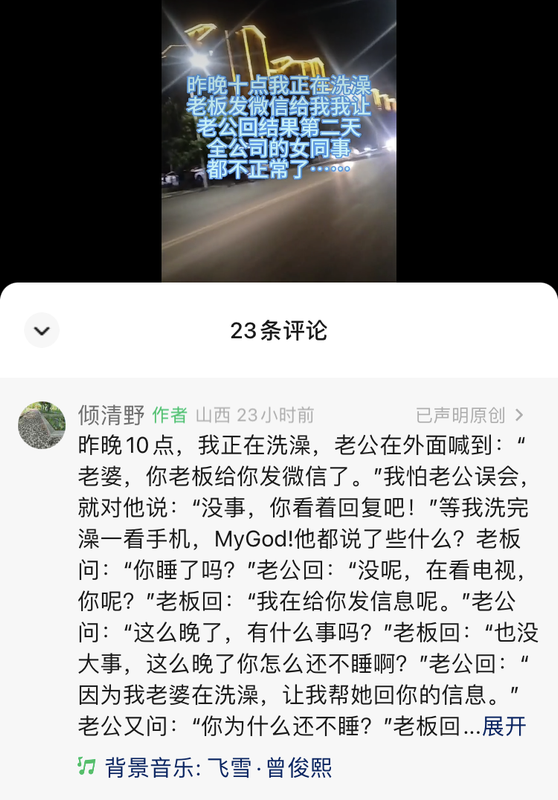
The article by TrumpFan attached below, is for me the most valuable post since I stepped into this BBS. Hereby please @TrumpFan allow me to copy here in order to bring up further extensive and meaningful discussion with other intellectuals.
It is not just to identify whether the IDs/BMs of langrener1 and sweetsister are MaskMen to each other or not, more importantly, it is a up-to-date topic around the world, about people profiling at social media, propaganda/manipulation, and counter-strike measurements for normal people. In fact, I have been long thinking of this topic, incl. social network virtual build-up strategy & psychological tactics. Those topics & research works must be long on top of agenda at CIA's state security or at Elon Musk's now to-be-called X-Company. Besides, I am even thinking about if the so-called "Butterfly Effect" can be predicted.
Warning: Any nonsense off-topic/nonsense replies will be deleted.
---------------------------------------------------------------
.It is not just to identify whether the IDs/BMs of langrener1 and sweetsister are MaskMen to each other or not, more importantly, it is a up-to-date topic around the world, about people profiling at social media, propaganda/manipulation, and counter-strike measurements for normal people. In fact, I have been long thinking of this topic, incl. social network virtual build-up strategy & psychological tactics. Those topics & research works must be long on top of agenda at CIA's state security or at Elon Musk's now to-be-called X-Company. Besides, I am even thinking about if the so-called "Butterfly Effect" can be predicted.
Warning: Any nonsense off-topic/nonsense replies will be deleted.
---------------------------------------------------------------
.
---------- viewtopic.php?p=1665669#p1665669 ----------
.
“或许”,因为证据不充分,只是一个初步判断。
我用Python把这两个id的所有发言和日期都下载导入到数据库。初看,发言风格差异大,但这看不出太多端倪,如果一个人要经营一个马甲,可以故意把语言风格弄的很不同。
我的依据主要是这三点:
1. 发帖时间。甜妈说她回国几个月,她4月2日-5月18日期间,没有发帖;从她前后发帖内容判断,她应该是在中国。
狼人4月份经常发帖,而且有时在中国的凌晨2点发帖。如果狼人是甜妈,很难想象一个带着娃的妈妈会在这个时段发帖。
2. 男女之别的关键信息。我尝试用几个区分男女的关键词测试这两个Id是否靠近。比如“b”大部分男生不在乎,“傻x”挂嘴里,但女生会比较敏感。
甜妈明确禁止版面用带“x”的字眼,比如傻x,左x,右x之类的

而狼人把x挂在嘴边,同时他如果当版主,表示“"我在网上查了一下。二x这个词约定俗成的意思是缺心眼。如果我是版主,不会对用这个词的ID封禁"
前面说了,一个人可以在养马甲的时候,可以故意说自己平时不说的词,把语言风格变得很不同。但是从甜妈对“美新版的执着来看,如果狼人是她,她应该不会允许让“x”成为一个版面政策。

3. 错词鉴别法。如果你打字的时候偶尔输出,那么下次输入法也有可能自动会把这个组合放到最前,对于一些无关紧要的词,我们经常将错就错。这些错词是一个人语言风格的独特标志,很多专业的文本鉴别方法之一就是错词鉴别。我试了几个,发现这两个id的错词重合度很低。比如狼人会把stillwandering叫“浪美”,不同日期叫过好几次,而甜妈就从来没有这么叫过。

--------------------
下面是他们的发帖时段,供大家参考
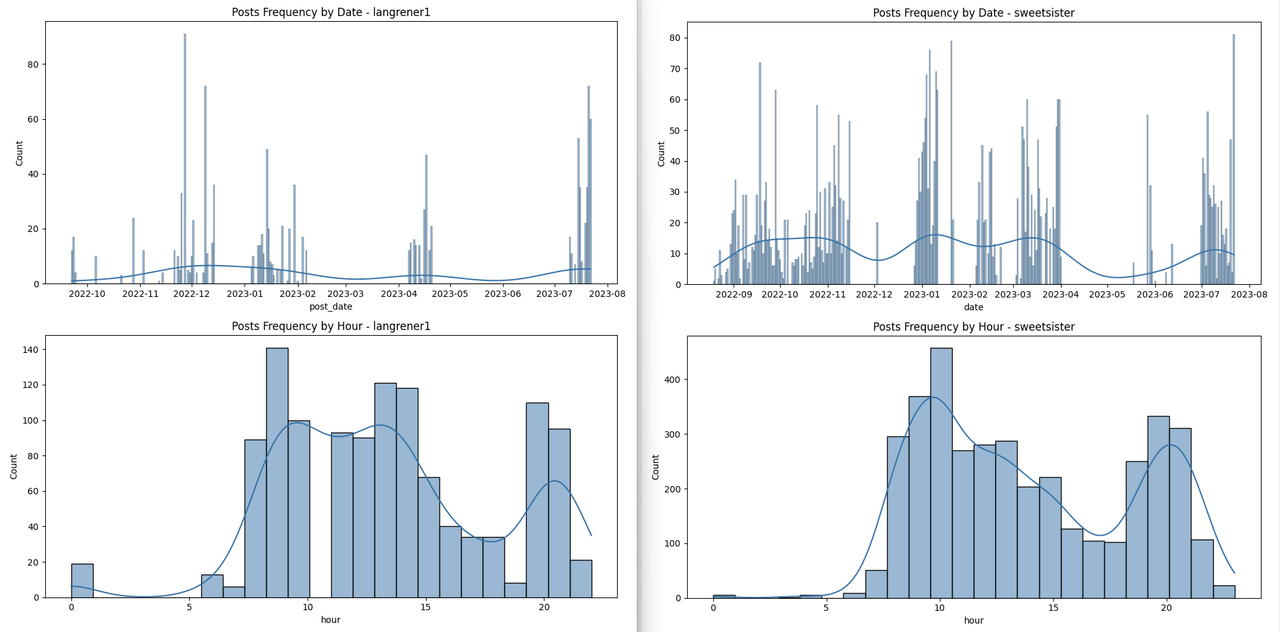
---------- viewtopic.php?p=1669204#p1669204 --------
.
虚词分析曾经很流行,但是现在forensic authorship attribution基本转向实词了,虚词仅仅是很次要的一个辅助。
原因有两点:1. 大部分人用虚词的方式其实差不多,个人痕迹并没有那么明显。比如你提到的“的”比重,你和甜妈的并没有统计意义上的显著性差异(我刚刚用python下载了你所有的发言,做了个Chi-squared test)
2. 就个人而言,虚词用法并不consistent,会因不同场合、不同时间而变化,并不具备持续的标志性
现在作者鉴定大部分都依赖具体内容、具体背景,个案分析,并没有一个标准化的流程,需要像侦探一样,根据个人特征制订分析方案
"Restricting our feature set to function words alone diminishes accuracy in each of our experiments by 5-10%.) The content features that prove to be most useful for gender discrimination are words related to technology (male) and words related to personal life or relationships (female)."
---------- viewtopic.php?p=1682207#p1682207 ---------
.
In terms of the tracking tool 马甲追踪 by 未名观察, it relied on "IP similarity" and "similar posting boards", which only proved useful before the old MITBBS underwent a system update to conceal users' IP addresses. Previously, it only hid the host ID but revealed the network ID. After the update, just the first number of the network ID was disclosed. Consequently, tracking user pseudonyms based on IP addresses became futile after this upgrade.
As mentioned before, traditional forensic linguistics placed considerable emphasis on computational techniques with the goal of crafting universally applicable tools. However, the outcomes were somewhat unconvincing because these digital methodologies didn't delve into the text's content and often overlooked the unique nuances each case presented. Currently, forensic linguistics leans towards adopting a mixed methods approach, evaluating on a case-by-case basis. The focus has shifted from focusing on the text exclusively to understanding its authors more deeply, incorporating larger context into their assessments.
My approach is a blend of both quantitative and qualitative strategies. For the quantitative part, I leverage Python, which houses the most extensive ecosystem—you'll find numerous libraries for data cleaning, statistics, and natural language processing.