STEM版,合并数学,物理,化学,科学,工程,机械。不包括生物、医学相关,和计算机相关内容。
版主: verdelite, TheMatrix
-
drifter楼主
- 论坛精英

- 帖子互动: 492
- 帖子: 7695
- 注册时间: 2022年 9月 1日 04:17
帖子
由 drifter楼主 »
看见有中文在ai训练有优势的说法
我猜应该是说 假定人类知识英文和中文内容相当 由于中文字少和组词的优势导致矩阵空间小很多 因而暴力运算要求要低一些
会不会open ai最近发布的模型被发现时不时转成中文跟这个有关
估计芯片禁运是根据英文需求制定的 没想到中文不需要那么多

x1

标签/Tags:
-
verdelite(闭关修炼中)
- 论坛元老

- 帖子互动: 1125
- 帖子: 25335
- 注册时间: 2022年 7月 21日 23:33
帖子
由 verdelite(闭关修炼中) »
drifter 写了: 2025年 2月 11日 01:58
看见有中文在ai训练有优势的说法
我猜应该是说 假定人类知识英文和中文内容相当 由于中文字少和组词的优势导致矩阵空间小很多 因而暴力运算要求要低一些
会不会open ai最近发布的模型被发现时不时转成中文跟这个有关
估计芯片禁运是根据英文需求制定的 没想到中文不需要那么多
我认为没道理。推理应该是以“意思”为单位的,而不是以字或者字母为单位的。
-
TheMatrix
- 论坛元老
2024年度优秀版主
TheMatrix 的博客
- 帖子互动: 299
- 帖子: 14012
- 注册时间: 2022年 7月 26日 00:35
帖子
由 TheMatrix »
verdelite 写了: 2025年 2月 11日 07:47
我认为没道理。推理应该是以“意思”为单位的,而不是以字或者字母为单位的。
这个不好说。
语言模型的输入和结果呈现都是字和字母。“意思”在中间层,它对不对谁也不知道,well,只能看它的呈现,所以还是语言,也就是字和字母。
不同语言对语言模型的performance可能是有影响的。
-
诺华老药工
- 著名点评

- 帖子互动: 509
- 帖子: 4814
- 注册时间: 2024年 2月 16日 09:08
帖子
由 诺华老药工 »
这所谓“推理”其实是“统计”和“某些词” (所谓的 prompting)发生联系的”概率”。所以我认为中文还是不一样的,而且使用人又多又集中。
观自在菩萨行深般若波罗蜜多时照见五蕴皆空度一切苦厄舍利子色不异空空不异色色即是空空即是色受想识亦复如是舍利子是诸法空相不生不灭不垢不淨不增不减是故空中无色无受想行识无眼耳鼻舌身意无色声香味触法无眼界乃至无意识界无无明亦无无明尽乃至无老死亦无老死尽无苦集灭道无智亦无得以无所得故菩提萨埵依般若波罗蜜多故心无罣碍无罣碍故无有恐怖远离颠倒梦想究竟涅槃三世诸佛依般若波罗蜜多故得阿耨多罗三藐三菩提故知般若波罗蜜多是大神咒是大明咒是无上咒是无等等咒能除一切苦真实不虚咒曰揭谛揭谛波罗揭谛波罗僧揭谛菩提萨婆诃
-
newwmkj2022(新未名口交)
- 著名点评
- 帖子互动: 215
- 帖子: 3746
- 注册时间: 2022年 8月 18日 20:50
帖子
由 newwmkj2022(新未名口交) »
“意思”就是黄金,文字和语言就是矿石,汉语算是富矿石,英语算是垃圾矿石,要提练出相同的数量的黄金(意思),需要富矿石(汉语)数量少,需要垃圾矿石(英语)多。
verdelite 写了: 2025年 2月 11日 07:47
我认为没道理。推理应该是以“意思”为单位的,而不是以字或者字母为单位的。
-
红烛歌楼
- 见习点评

- 帖子互动: 90
- 帖子: 2025
- 注册时间: 2024年 9月 18日 21:29
帖子
由 红烛歌楼 »
对比一下为表述相同意思的文章,中英文训练出来的模型的参数量即可
x1
此网站Yesterday 写了: ↑
(得了癌症)复发也可以治,治愈本来就不应该是目标。
得了癌症治疗的目标本来就是不应该治愈,那是啥?还复发也可以治?什么鬼?别说复发,就说第一次被诊断出xxCa.,多少人当场崩溃?还复发可以治?我几个亲戚都是复发了人完了,怎么不治了?推诿回家等S呢?
-
xexz
- 论坛精英
- 帖子互动: 391
- 帖子: 6746
- 注册时间: 2022年 7月 30日 11:48
-
联系:
帖子
由 xexz »
红烛歌楼 写了: 2025年 2月 11日 21:19
对比一下为表述相同意思的文章,中英文训练出来的模型的参数量即可
联合国同一官方文本纸制媒体的厚度,算官方证据,没有异议。
-
xexz
- 论坛精英
- 帖子互动: 391
- 帖子: 6746
- 注册时间: 2022年 7月 30日 11:48
-
联系:
帖子
由 xexz »
xexz 写了: 2025年 2月 12日 00:27
联合国同一官方文本纸制媒体的厚度,算官方证据,没有异议。
原来学汉语,不说变聪明,至少反应快,你们为什么不学呢?
难吗?不难呀,分析语的词法、语法规矩多了呀。
-
drifter楼主
- 论坛精英
- 帖子互动: 492
- 帖子: 7695
- 注册时间: 2022年 9月 1日 04:17
帖子
由 drifter楼主 »
xexz 写了: 2025年 2月 12日 00:32
原来学汉语,不说变聪明,至少反应快,你们为什么不学呢?
难吗?不难呀,分析语的词法、语法规矩多了呀。
你们是谁啊?
x1

-
xexz
- 论坛精英
- 帖子互动: 391
- 帖子: 6746
- 注册时间: 2022年 7月 30日 11:48
-
联系:
帖子
由 xexz »
drifter 写了: 2025年 2月 12日 00:33
你们是谁啊?
不想学中文的蠢货呀,
你这个人,怎么明知故问呀。
-
drifter楼主
- 论坛精英
- 帖子互动: 492
- 帖子: 7695
- 注册时间: 2022年 9月 1日 04:17
帖子
由 drifter楼主 »
xexz 写了: 2025年 2月 12日 00:40
不想学中文的蠢货呀,
你这个人,怎么明知故问呀。
那你应该用英文或别的语言发 这里的人好像都学过中文
-
drifter楼主
- 论坛精英
- 帖子互动: 492
- 帖子: 7695
- 注册时间: 2022年 9月 1日 04:17
帖子
由 drifter楼主 »
红烛歌楼 写了: 2025年 2月 11日 21:19
对比一下为表述相同意思的文章,中英文训练出来的模型的参数量即可
这应该很容易测试 就拿楼上提到的联合国官方文件来测试
-
xexz
- 论坛精英
- 帖子互动: 391
- 帖子: 6746
- 注册时间: 2022年 7月 30日 11:48
-
联系:
帖子
由 xexz »
drifter 写了: 2025年 2月 12日 00:44
那你应该用英文或别的语言发 这里的人好像都学过中文

太直接了,说中文的人一般都很含蓄,
看破不说破,打人不打脸,有话说一半,日后好相见。
所谓的难,难在文化差异太大,人本主义的性善论文化,
对西方人来说,就象进入异次元空间。
即使是真相也不需要所有人都知道,这个就叫含蓄。
-
tops
- 著名写手

- 帖子互动: 24
- 帖子: 283
- 注册时间: 2023年 12月 13日 01:01
帖子
由 tops »
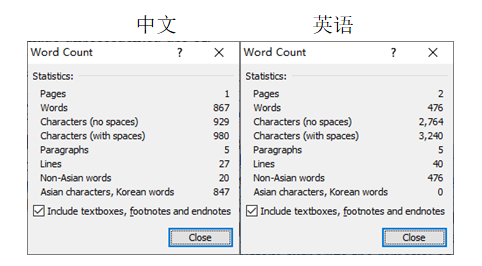
如下图5段英语文字机器翻译成中文后word count,算token好像英语有优势,真正的机器运输怎样咱就不懂了。
-
Trump(敌在本能寺)
- 论坛支柱

- 帖子互动: 1076
- 帖子: 11811
- 注册时间: 2022年 8月 1日 22:00
帖子
由 Trump(敌在本能寺) »
tops 写了: 2025年 2月 12日 03:17
如下图5段英语文字机器翻译成中文后word count,算token好像英语有优势,真正的机器运输怎样咱就不懂了。
这是英文跟韩文比,不是中文
郁孤台下清江水,中间多少行人泪。刘郎已恨蓬山远,更隔蓬山一万重。
-
drifter楼主
- 论坛精英
- 帖子互动: 492
- 帖子: 7695
- 注册时间: 2022年 9月 1日 04:17
帖子
由 drifter楼主 »
tops 写了: 2025年 2月 12日 03:17
如下图5段英语文字机器翻译成中文后word count,算token好像英语有优势,真正的机器运输怎样咱就不懂了。
我觉得内容多了之后 英文字涨很快 尤其涉及各项专业知识 内容少不明显
对通用大模型影响大
-
ccmath
- 论坛精英
- 帖子互动: 404
- 帖子: 7645
- 注册时间: 2022年 9月 17日 19:18
帖子
由 ccmath »
根本应该在于中文用现成汉字造新词,并且在保留意义的基础上高度压缩的能力很强
比如甲亢,英文的hyperthyroidism 如果不做词根切割,就是一个 token , 日文的名词“甲状腺機能亢進症”不能压缩,结果字数太多,被各种片假名取代。但是中文在单字的基础上,造的新词层出不穷,比如“自干五”。
过去中文处理有个切分词的问题,现在每个词自成 token, 反而成了优势
drifter 写了: 2025年 2月 11日 01:58
看见有中文在ai训练有优势的说法
我猜应该是说 假定人类知识英文和中文内容相当 由于中文字少和组词的优势导致矩阵空间小很多 因而暴力运算要求要低一些
会不会open ai最近发布的模型被发现时不时转成中文跟这个有关
估计芯片禁运是根据英文需求制定的 没想到中文不需要那么多
-
drifter楼主
- 论坛精英
- 帖子互动: 492
- 帖子: 7695
- 注册时间: 2022年 9月 1日 04:17
帖子
由 drifter楼主 »
ccmath 写了: 2025年 2月 12日 14:59
根本应该在于中文用现成汉字造新词,并且在保留意义的基础上高度压缩的能力很强
比如甲亢,英文的hyperthyroidism 如果不做词根切割,就是一个 token , 日文的名词“甲状腺機能亢進症”不能压缩,结果字数太多,被各种片假名取代。但是中文在单字的基础上,造的新词层出不穷,比如“自干五”。
过去中文处理有个切分词的问题,现在每个词自成 token, 反而成了优势
是的
组词新词规则就那么些 而且ai最擅长这种模糊规则
相对于海量新词来讲 对数级的优势
-
ccmath
- 论坛精英
- 帖子互动: 404
- 帖子: 7645
- 注册时间: 2022年 9月 17日 19:18
帖子
由 ccmath »
Deepseek 的做法,mixture of experts, token 集合的高度重复是个有利条件
就像会汉字的中国人看不熟悉的专业书,凭着懂汉字也能猜出点意思
美国人,日本人,如果词汇量不够就完全是天书
drifter 写了: 2025年 2月 12日 15:29
是的
组词新词规则就那么些 而且ai最擅长这种模糊规则
相对于海量新词来讲 对数级的优势
-
FoxMe(令狐)
- 论坛精英
- 帖子互动: 158
- 帖子: 5683
- 注册时间: 2022年 7月 26日 16:46
帖子
由 FoxMe(令狐) »
属实。
文言文是最高效的语言,现在的白话文已经退化了。文言文极为紧凑,不用标点,妥妥的数据压缩高科技。
ccmath 写了: 2025年 2月 12日 19:12
Deepseek 的做法,mixture of experts, token 集合的高度重复是个有利条件
就像会汉字的中国人看不熟悉的专业书,凭着懂汉字也能猜出点意思
美国人,日本人,如果词汇量不够就完全是天书


