近日,OpenAI 再次陷入了舆论风波。
事件源于 LessWrong 论坛上的一则爆料。一位名为「Meemi」的 Epoch AI 承包商透露,OpenAI 不仅为 FrontierMath 基准测试提供资金支持,还获得了测试题库的特权访问权。
而这或许也是 o3 的成绩在短时间内获得极大提高的重要原因。但这个信息直到 去年 12 月 20 日 o3 发布时,才由 Epoch AI 对外公布。
消息一出,瞬间在 AI 圈引起轩然大波。
因为这很难不让网友怀疑 OpenAI 是既当裁判,也当选手。吃瓜之前,需要给不熟悉的朋友先捋事件的背景信息。
去年 12 月,OpenAI 正式发布了新一代号称突破 AI 极限的 o3 模型。
在其中一项名为 FrontierMath 的 AI 数学基准测试(成绩单)中,OpenAI 以 25.2% 的准确率遥遥领先,远超 GPT-4 和 Gemini 等模型不足 2% 的成绩。
OpenAI 最强模型被曝造假!提前获取测试题,顶级数学家被蒙在鼓里
版主: Softfist
#2 Re: OpenAI 最强模型被曝造假!提前获取测试题,顶级数学家被蒙在鼓里
FrontierMath 是一个分量极重的高级数学推理能力评估基准。它由 Epoch AI 联手 60 多位顶级数学家共同打造,参与者包括多位菲尔兹奖得主和国际数学奥林匹克竞赛的资深命题人。
该基准包含数百个原创且极具挑战性的数学问题,覆盖现代数学的多个主要分支,如数论、实分析、代数几何、范畴论等。
2006 年菲尔兹奖得主、数学天才陶哲轩曾评价 FrontierMath 的问题「极其具有挑战性」,并认为这些问题只能由领域专家来解决。
他指出,即使是人类专家,解决这些问题也需要数小时甚至数天的努力。
该基准包含数百个原创且极具挑战性的数学问题,覆盖现代数学的多个主要分支,如数论、实分析、代数几何、范畴论等。
2006 年菲尔兹奖得主、数学天才陶哲轩曾评价 FrontierMath 的问题「极其具有挑战性」,并认为这些问题只能由领域专家来解决。
他指出,即使是人类专家,解决这些问题也需要数小时甚至数天的努力。
我是腐驴受 家住恒河边
腐是腐驴的腐呀
受是腐驴受的受
腐是腐驴的腐呀
受是腐驴受的受
-
Caravel
- 论坛元老

Caravel 的博客 - 帖子互动: 702
- 帖子: 27635
- 注册时间: 2022年 7月 24日 17:21
#3 Re: OpenAI 最强模型被曝造假!提前获取测试题,顶级数学家被蒙在鼓里
这个很令人不齿fulvshou 写了: 2025年 1月 19日 23:54 近日,OpenAI 再次陷入了舆论风波。
事件源于 LessWrong 论坛上的一则爆料。一位名为「Meemi」的 Epoch AI 承包商透露,OpenAI 不仅为 FrontierMath 基准测试提供资金支持,还获得了测试题库的特权访问权。
而这或许也是 o3 的成绩在短时间内获得极大提高的重要原因。但这个信息直到 去年 12 月 20 日 o3 发布时,才由 Epoch AI 对外公布。
消息一出,瞬间在 AI 圈引起轩然大波。
因为这很难不让网友怀疑 OpenAI 是既当裁判,也当选手。吃瓜之前,需要给不熟悉的朋友先捋事件的背景信息。
去年 12 月,OpenAI 正式发布了新一代号称突破 AI 极限的 o3 模型。
在其中一项名为 FrontierMath 的 AI 数学基准测试(成绩单)中,OpenAI 以 25.2% 的准确率遥遥领先,远超 GPT-4 和 Gemini 等模型不足 2% 的成绩。
等于偷看答案
#4 Re: OpenAI 最强模型被曝造假!提前获取测试题,顶级数学家被蒙在鼓里
Apple去年的paper说了,美国大模型主要靠偷看测试数据提高成绩。。。
fulvshou 写了: 2025年 1月 19日 23:54 近日,OpenAI 再次陷入了舆论风波。
事件源于 LessWrong 论坛上的一则爆料。一位名为「Meemi」的 Epoch AI 承包商透露,OpenAI 不仅为 FrontierMath 基准测试提供资金支持,还获得了测试题库的特权访问权。
而这或许也是 o3 的成绩在短时间内获得极大提高的重要原因。但这个信息直到 去年 12 月 20 日 o3 发布时,才由 Epoch AI 对外公布。
消息一出,瞬间在 AI 圈引起轩然大波。
因为这很难不让网友怀疑 OpenAI 是既当裁判,也当选手。吃瓜之前,需要给不熟悉的朋友先捋事件的背景信息。
去年 12 月,OpenAI 正式发布了新一代号称突破 AI 极限的 o3 模型。
在其中一项名为 FrontierMath 的 AI 数学基准测试(成绩单)中,OpenAI 以 25.2% 的准确率遥遥领先,远超 GPT-4 和 Gemini 等模型不足 2% 的成绩。
-
民主自由是婊子的遮羞布(谁的帝)

- 论坛元老
- 帖子互动: 1092
- 帖子: 16710
- 注册时间: 2022年 8月 31日 10:43
#5 Re: OpenAI 最强模型被曝造假!提前获取测试题,顶级数学家被蒙在鼓里
这尼玛一定是假新闻fulvshou 写了: 2025年 1月 19日 23:54 近日,OpenAI 再次陷入了舆论风波。
事件源于 LessWrong 论坛上的一则爆料。一位名为「Meemi」的 Epoch AI 承包商透露,OpenAI 不仅为 FrontierMath 基准测试提供资金支持,还获得了测试题库的特权访问权。
而这或许也是 o3 的成绩在短时间内获得极大提高的重要原因。但这个信息直到 去年 12 月 20 日 o3 发布时,才由 Epoch AI 对外公布。
消息一出,瞬间在 AI 圈引起轩然大波。
因为这很难不让网友怀疑 OpenAI 是既当裁判,也当选手。吃瓜之前,需要给不熟悉的朋友先捋事件的背景信息。
去年 12 月,OpenAI 正式发布了新一代号称突破 AI 极限的 o3 模型。
在其中一项名为 FrontierMath 的 AI 数学基准测试(成绩单)中,OpenAI 以 25.2% 的准确率遥遥领先,远超 GPT-4 和 Gemini 等模型不足 2% 的成绩。
民主国家不会作的
-老逼将
你帝,我帝,他帝,谁的帝?



-
wanmeishijie(石昊)
- 论坛元老
wanmeishijie 的博客 - 帖子互动: 2311
- 帖子: 71970
- 注册时间: 2022年 12月 10日 23:58
#10 Re: OpenAI 最强模型被曝造假!提前获取测试题,顶级数学家被蒙在鼓里
曝光者,背后中八枪自杀,基佬CEO药丸
理解了老将是代入狗的视角之后,你就理解了老将
viewtopic.php?t=120513
理解了它们是代入狗的视角之后,它们为什么会嘲笑不愿意当狗的人,以及为什么会害怕想要反抗的人,就都可以理解了:
“放着好好的狗不当”


#14 Re: OpenAI 最强模型被曝造假!提前获取测试题,顶级数学家被蒙在鼓里
王孟源说
AI是在网上亿万篇文章中查找最可能的答案
AI推理是有错误率的
错误率每减少一半,需要十几二十次方的能量
这个不可持续
AI是在网上亿万篇文章中查找最可能的答案
AI推理是有错误率的
错误率每减少一半,需要十几二十次方的能量
这个不可持续
#15 OpenAI o3被曝提前获取测试题,在FrontierMath的成绩被质疑。
https://news.mydrivers.com/1/1026/1026259.htm
OpenAI o3还没上线,就被曝数学成绩是靠作弊得来?!
Benchmark发布机构内部人员爆料称,OpenAI给了他们经费赞助。
就连包括陶哲轩在内参与出题的60余名数学家,在消息曝光之前也都和普通公众一样蒙在鼓里。
直到o3发布,这一消息才被公开。这意味着严格保密的题目,OpenAI提前拿到了手中。

这套数学题集名叫FrontierMath,包含了由陶哲轩等60多名权威数学家命制的高难度题目。
陶哲轩就表示,这些题目足够困扰AI几年的时间;1998年菲尔斯奖得主Gowers也说,能解决其中的一个问题就已经超越现在的能力范围了。
当时也正是因为在这一测试基准上大幅领先,o3的能力更进一步被得到认可。

Epoch.ai这边,联合创始人Tamay Besiroglu也回应并承认了秘密赞助和OpenAI提前拿到题目的传闻,但否认题目被OpenAI拿来作弊。
但有些网友并不买账,表示OpenAI如果不使用这些信息还要访问权限干什么,并推测有可能被用来训练。
专家被要求严格保密,但OpenAI却能拿到题
这家名叫Epoch.ai的机构,开发了一款名为FrontierMath的数学测试基准,论文第一版预印本于去年11月7日发布。
包括第一版在内,FrontierMath的论文在近两个月的时间里一共发布了五个版本,但直到最后12月20日的第五版才披露了OpenAI的资助。

不过也只是在脚注中提了一句,感谢OpenAI对构建Benchmark的支持。

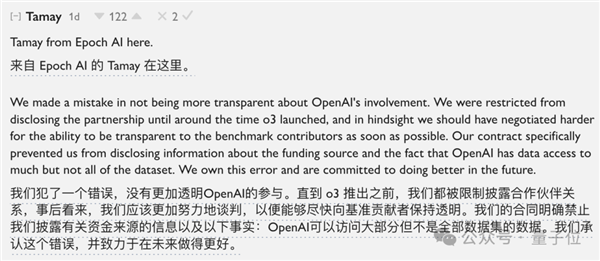
并且12月20日刚好是OpenAI发布o3的日子,并且Besiroglu也透露,之前没有公开正是由于OpenAI的保密要求:
“在o3推出之前,我们一直被限制披露合作关系,事后看来,我们应该更加努力地谈判,以便能够尽快向基准贡献者保持透明。”
如果不看OpenAI这场风波,FrontierMath是一套含金量非常高的测试基准,由全球六十余位数学家联手命题,包括教授、IMO命题人、菲尔兹奖获得者,其中就有大牛陶哲轩等人。
而且难度也非常高,包括数百个极具挑战性的数学问题,在o3之前的模型解决率不到2%。
哪怕o3真的作了弊,得分也才20多分。

像下面的这道题目,在FrontierMath当中算是难度最低的一档:

正常来说,FrontierMath里的题目和答案是严格保密的,就连出题的数学家也被要求签订保密协议,甚至不能使用Overleaf、Colab或电子邮件传输有关题目的信息。
讽刺的是,这样“严格保密”的题目却被OpenAI拿到,而出题专家对OpenAI的情况毫不知情。
斯坦福博士、MIT罗德奖学金得主Carina Hong(洪乐潼)就表示,至少有六名专家能够证实这一点,并且大部分专家表示不确定如果知道(OpenAI的独家访问权)是否还会选择贡献出题。

后来她表示,(和出题人)签保密协议确实是为了防止数据污染,对OpenAI的目的则不做猜测。

内部爆料和外部质疑之下,Epoch.ai联创Besiroglu也承认了和OpenAI存在秘密协议,并表示没有公开透明确实是“犯了一个错误”。
但Epoch.ai否认了OpenAI作弊的说法,表示一方面OpenAI拿到的数据并不是全部,另一方面OpenAI也口头承诺拿到的数据不会用于模型训练。
Besiroglu回应全文如下(中文为机翻):

但对于Besiroglu提到的“口头承诺”,有网友表示至少要有个书面的协议,但猜测OpenAI不会愿意提供,还有人补充说哪怕有书面材料也很难监督实施。
不过到现在,确实是所有的回应都来自Epoch.ai这边,OpenAI还没给出说明。

另外Epoch.ai首席数学家Ellot Glazer也承诺,之后会对受到的资助进行说明。
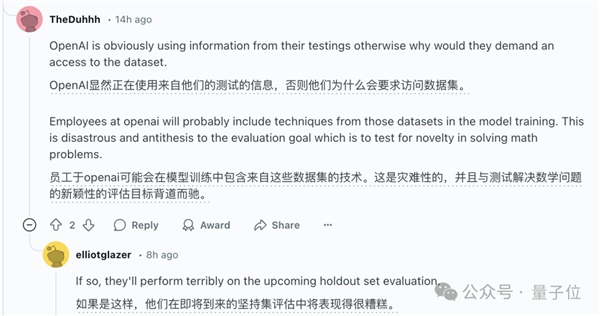
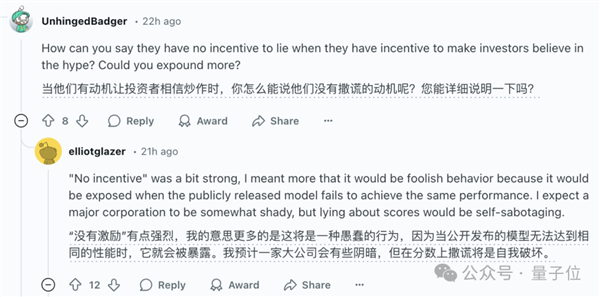
对于o3的成绩,Ellot表示Epoch.ai无法给出承诺,但他个人相信OpenAI的报告是准确的,因为在他看来OpenAI“没有撒谎的动机”。
同时他说Epoch.ai正在开发一个保留数据集,能够确保OpenAI在测试之前无法事先接触。

不过有网友对“没有动机”的说法表示怀疑。Ellot也进行了解释,表示OpenAI没有傻到搬起石头砸自己的脚。
OpenAI o3还没上线,就被曝数学成绩是靠作弊得来?!
Benchmark发布机构内部人员爆料称,OpenAI给了他们经费赞助。
就连包括陶哲轩在内参与出题的60余名数学家,在消息曝光之前也都和普通公众一样蒙在鼓里。
直到o3发布,这一消息才被公开。这意味着严格保密的题目,OpenAI提前拿到了手中。
这套数学题集名叫FrontierMath,包含了由陶哲轩等60多名权威数学家命制的高难度题目。
陶哲轩就表示,这些题目足够困扰AI几年的时间;1998年菲尔斯奖得主Gowers也说,能解决其中的一个问题就已经超越现在的能力范围了。
当时也正是因为在这一测试基准上大幅领先,o3的能力更进一步被得到认可。
Epoch.ai这边,联合创始人Tamay Besiroglu也回应并承认了秘密赞助和OpenAI提前拿到题目的传闻,但否认题目被OpenAI拿来作弊。
但有些网友并不买账,表示OpenAI如果不使用这些信息还要访问权限干什么,并推测有可能被用来训练。
专家被要求严格保密,但OpenAI却能拿到题
这家名叫Epoch.ai的机构,开发了一款名为FrontierMath的数学测试基准,论文第一版预印本于去年11月7日发布。
包括第一版在内,FrontierMath的论文在近两个月的时间里一共发布了五个版本,但直到最后12月20日的第五版才披露了OpenAI的资助。
不过也只是在脚注中提了一句,感谢OpenAI对构建Benchmark的支持。
并且12月20日刚好是OpenAI发布o3的日子,并且Besiroglu也透露,之前没有公开正是由于OpenAI的保密要求:
“在o3推出之前,我们一直被限制披露合作关系,事后看来,我们应该更加努力地谈判,以便能够尽快向基准贡献者保持透明。”
如果不看OpenAI这场风波,FrontierMath是一套含金量非常高的测试基准,由全球六十余位数学家联手命题,包括教授、IMO命题人、菲尔兹奖获得者,其中就有大牛陶哲轩等人。
而且难度也非常高,包括数百个极具挑战性的数学问题,在o3之前的模型解决率不到2%。
哪怕o3真的作了弊,得分也才20多分。
像下面的这道题目,在FrontierMath当中算是难度最低的一档:
正常来说,FrontierMath里的题目和答案是严格保密的,就连出题的数学家也被要求签订保密协议,甚至不能使用Overleaf、Colab或电子邮件传输有关题目的信息。
讽刺的是,这样“严格保密”的题目却被OpenAI拿到,而出题专家对OpenAI的情况毫不知情。
斯坦福博士、MIT罗德奖学金得主Carina Hong(洪乐潼)就表示,至少有六名专家能够证实这一点,并且大部分专家表示不确定如果知道(OpenAI的独家访问权)是否还会选择贡献出题。
后来她表示,(和出题人)签保密协议确实是为了防止数据污染,对OpenAI的目的则不做猜测。
内部爆料和外部质疑之下,Epoch.ai联创Besiroglu也承认了和OpenAI存在秘密协议,并表示没有公开透明确实是“犯了一个错误”。
但Epoch.ai否认了OpenAI作弊的说法,表示一方面OpenAI拿到的数据并不是全部,另一方面OpenAI也口头承诺拿到的数据不会用于模型训练。
Besiroglu回应全文如下(中文为机翻):
但对于Besiroglu提到的“口头承诺”,有网友表示至少要有个书面的协议,但猜测OpenAI不会愿意提供,还有人补充说哪怕有书面材料也很难监督实施。
不过到现在,确实是所有的回应都来自Epoch.ai这边,OpenAI还没给出说明。
另外Epoch.ai首席数学家Ellot Glazer也承诺,之后会对受到的资助进行说明。
对于o3的成绩,Ellot表示Epoch.ai无法给出承诺,但他个人相信OpenAI的报告是准确的,因为在他看来OpenAI“没有撒谎的动机”。
同时他说Epoch.ai正在开发一个保留数据集,能够确保OpenAI在测试之前无法事先接触。
不过有网友对“没有动机”的说法表示怀疑。Ellot也进行了解释,表示OpenAI没有傻到搬起石头砸自己的脚。