
现在每天大量的人查询LLM,按照统计学应该有很多查询都是一样的关键字,那么问题是:现在的AI/LLM有没有有效的缓存机制,使得这些类似查询不需要每次都消耗宝贵的tokens,而是通过缓存输出最终结果?
有谁有此类研究/实操经验?
版主: hci

webdriver 写了: 2025年 8月 21日 21:49现在每天大量的人查询LLM,按照统计学应该有很多查询都是一样的关键字,那么问题是:现在的AI/LLM有没有有效的缓存机制,使得这些类似查询不需要每次都消耗宝贵的tokens,而是通过缓存输出最终结果?
有谁有此类研究/实操经验?
cache大量数据也需要耗费能量
况且很难找到完全一样的query
你大概关心的是RAG类产品,查询query先被rewrite成一堆sub query,用来找context,这部分可以cache。但之后的rerank和summarization等步骤不太能被cache,除非原始query是perfect match。
LLM inference engine主要是做prefix cache,能减少system prompt的处理消耗,但完整的结果很难cache。

楼主估计没有了解当前LLM的基础模型Transformer。简单地说基于前面的若干个token t-1,...t-n(n是context的长度)找到可能性最大的几个token,然后再从这几个token中,按照一定的分布率(由temperature参数控制,取值越大随机性越强)选一个当作输出token t。这个token t 和以前的n-1个合并一起,再次调用Transformer模型,得到token t+1。反复如此,得到一个完全的输出。
所以LLM的结果每次都是实时生成的。
Subquery那一层(Expert?Module?Agent?)可以cache。举例说调用Web search,结果显然是cached了的。
fantasist 写了: 2025年 8月 22日 19:48你大概关心的是RAG类产品,查询query先被rewrite成一堆sub query,用来找context,这部分可以cache。但之后的rerank和summarization等步骤不太能被cache,除非原始query是perfect match。
LLM inference engine主要是做prefix cache,能减少system prompt的处理消耗,但完整的结果很难cache。
肯定的
Yes, the responses from a large language model (LLM) like me are generated in real time. Here's a breakdown:
No pre-written answers: Unlike a database, I don’t retrieve a stored answer. Each reply is generated dynamically based on your input.
Token-by-token generation: The model predicts the next word (or “token”) one at a time until the response is complete. This is why longer answers can take a moment to appear.
Context-dependent: The response depends on the conversation history, so even the same question may get slightly different answers depending on prior messages.
External tools: If an LLM query uses external tools (like browsing or APIs), part of the result might come from a live lookup, but the final output is still assembled in real time.
说句不好听的,有了chatGPT之后,大多数人都跟傻子差不多
fantasist 写了: 2025年 8月 22日 14:50你要的是传统search。
LLM本身生成就带有随机性,主要由temperature控制。不适合强行cache住某个response。
琐男们不了解随机(算法)的强大。哪怕是(鸣笑)西爱死大师学位,老牛敢说99%以上也不了解。也许90%以上的西爱死永久脑残也不清楚。
现在的AI之所以强大,一半功劳在于对计算机而言貌似随机的prompt输入。这是药引。
随机是尖端技术/思想。曼哈顿工程里就很有名。
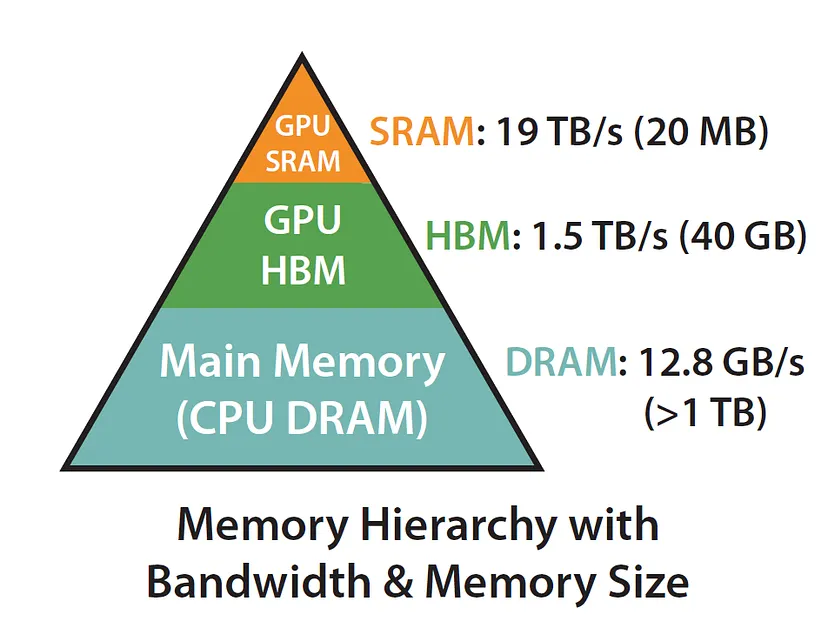
即使是1+1=2這種問題,context history不一樣,輸出結果也不一樣,這就是LLM的魅力。你說的cache,有類似的flash attention實現,不是緩存結果,而是規劃利用系統的memory hierarchy,來加速模型。你說的結果cache只能放在CPU DRAM裡面,如果hit rate過低,將會浪費大量系統內存。如果放在GPU HBM裡面,那是不可能的,因為GPU HBM非常緊張,沒空間放這種東西。如果做成Vector Datbase,放在硬盤上,那就是RAG,但對GPU提升性能沒有影響,因為HBM速度比硬盤快幾個數量級。所以我總說,不懂硬件底層的,最好不要出來設計AI系統,否則只能越改越糟。
好多大牛啊。。。
话说我这个话题其实想知道的是不是有这样挣钱的机会,就是提供中间层服务(agent type/VAR)接受终端用户咨询,可以是非常专门的领域;后端与商用LLM的通讯是以token数量计费的,如果你自己的算法可以提供buffering/caching,那么可以节省不少实时查询的成本,毕竟你是知道终端用户们的需求,你的结果是相对确定的 -- 以前是专门定制的数据库/资料库,现在是LLM backed。








